This is part two of the Building a Voice-Driven TV Remote series:
- Getting The Data
- Adding Search
- The Device API
- Some Basic Alexa Commands
- Adding a Listings Search Command
- Starting to Migrate from HTTP to MQTT
- Finishing the Migration from HTTP to MQTT
- Tracking Performance with Application Insights
In part one of this series I showed how I created a system to pull in channel and listing data on a daily basis and store that in a database. The next step for this is to enable easy searching over that data. While I could do this directly against SQL Server itself, it would be better to use Azure Search to enable better full text search and language processing features.
As I mentioned in part one, keeping costs down is a key factor in the design here. Azure Search offers a free tier that provides 10,000 documents, 3 indexes, and 50MB of storage. While this isn't a ton, it's actually more than enough for my needs here.
The Search Service
Another nice thing about Search Service is that it makes it trivial to connect your indexes to other data sources within Azure, so I was able to quickly create two indexes, channels and shows, and specify that they should pull from the associated tables in SQL Server created in the previous post. When you create the indexes you can also specify which fields get indexed, and also which can be used for filtering, sorting, and searching. There are other things you can provide as well, such as customizing scoring profiles, but there's no need to get into that arena for now.
Once you add your indexes and the indexers pull in your data you can immediately start querying the data directly through the Azure portal:
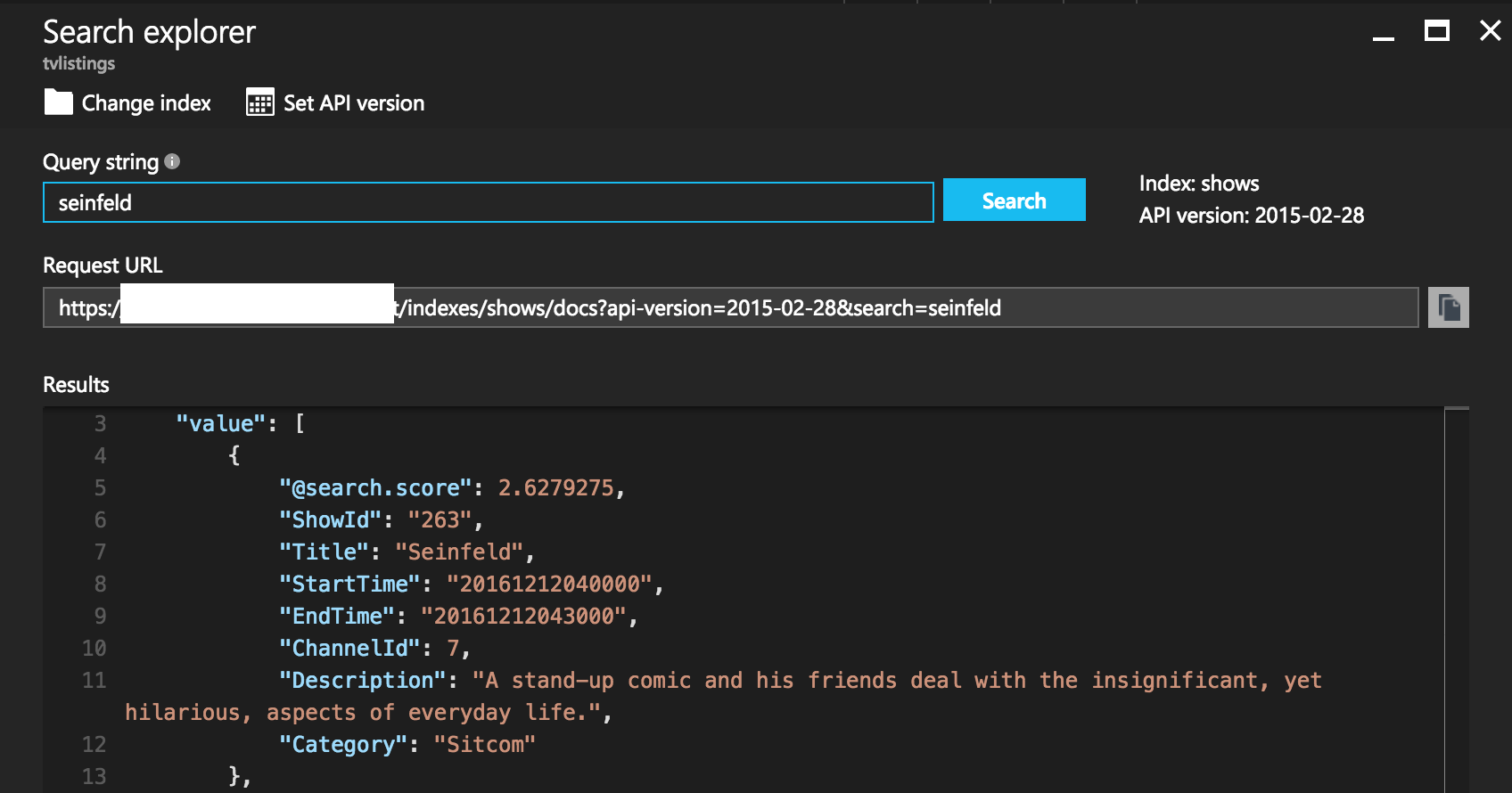
After importing my data I also realized that I had room within the service to import more than a single day's worth of data, which is great since being able to index two days at a time means not having to worry about having a short period of no data around midnight. Even keeping two days of data right now provides a bit of headroom on document count, and a ton of room on storage size:
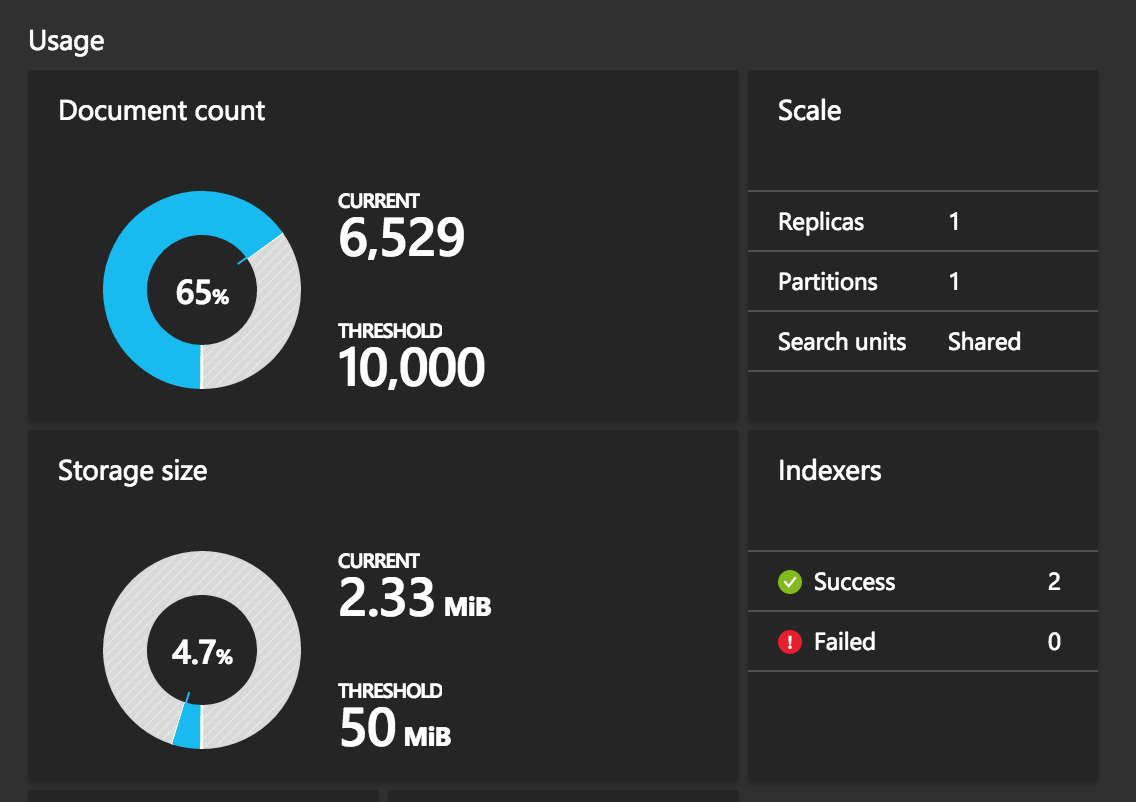
There's undoubtedly a lot more I can do and optimize here, but it's more than adequate as a starting point to get things moving.
Re-Indexing
Each time you run an indexer it appends the data it finds to the existing data set, rather than replacing it. Unfortunately there's also currently no simple way of purging an index, so the current advice is to tear down and recreate the index if this is something you need. There's an issue here you can vote on (and you should) if this is something you'd like to see supported as a built-in feature. Since there aren't that many documents in the index, I opted to programmatically delete everything in the index each time I update the data, in order to avoid having to reconnect data sources and all that.
ImportLineup Function
Either way, the indexing functionality needs to be triggered after the ImportLineup function created in part one completes. While I could have just appended that functionality to ImportLineup itself, it's much cleaner to make it a separate discrete task. This also allows me the flexibility to easy run it on its own if need be as well.
To facilitate this, I chose to make use of a queue. When ImportLineup finishes it will place an item into a queue that will get picked up by the RebuildSearchIndex function we'll create shortly. This is done with the following in function.json:
{
"type": "queue",
"name": "outputQueueItem",
"queueName": "rebuild-requests",
"connection": "tvlistingstorage_STORAGE",
"direction": "out"
}
Next, I'll make two small tweaks to the function implementation itself. First, I need to modify the signature to account for the new out parameter:
let Run(xml: string, name: string, log: TraceWriter, outputQueueItem: byref<string>) =
Finally, at the end of the function I place an item in the queue that contains the name of the file that triggered the import to make it easy to trace the flow across functions:
outputQueueItem <- name
That's all that has to change in ImportLineup, since we're just changing the output state and leaving the details of the function itself alone.
RebuildSearchIndex Function
Next we'll need the RebuildSearchIndex function that reads out of that queue and updates the search index. Here's the function input definition from function.json:
{
"bindings": [
{
"name": "inputMessage",
"type": "queueTrigger",
"direction": "in",
"queueName": "rebuild-requests",
"connection": "tvlistingstorage_STORAGE"
}
],
"disabled": false
}
We'll also need a project.json to pull in some dependencies:
{
"frameworks": {
"net46": {
"dependencies": {
"FSharp.Data": "2.3.2",
"Newtonsoft.Json": "9.0.1"
}
}
}
}
Naturally I'm including FSharp.Data again, but you'll also see Newtonsoft.Json here as well. I originally wrote this function to use the JSON type provider, but unfortunately ran into some issues getting this to work in the function. Once I can work through these I'll definitely rework the function to use the type provider again since it's awesome. For now I'll make due with Json.NET.
First, the function needs to define some models:
open System
open FSharp.Data
open FSharp.Data.HttpRequestHeaders
open Newtonsoft.Json
type SearchRequest = { filter: string; top: int; search: string; }
type SearchResult = { ShowId: string }
type SearchResponse = { value: SearchResult array }
type DeleteOperation = { [<JsonProperty(PropertyName = "@search.action")>] Action: string; ShowId: string }
type DeleteRequest = { value: DeleteOperation array }
The function will interact with Azure Search via its REST API which exposes a lot of functionality, including some OData search capabilities. The models here line up with the requests and responses for the handful of operations we'll need here.
Each call to the API requires sending in an API key, so I'll also define a little HTTP helper that POSTs some JSON and includes the key:
let postJson urlPath json =
let url = sprintf "%s/%s" (Environment.GetEnvironmentVariable("SearchUrlBase")) urlPath
let apiKeyHeader = "api-key", (Environment.GetEnvironmentVariable("SearchApiKey"))
Http.RequestString(url,
body = TextRequest json,
headers = [ ContentType HttpContentTypes.Json; apiKeyHeader ])
Next, a function to search the index:
let search query filter count =
let json = JsonConvert.SerializeObject({ filter = filter; top = count; search = query })
postJson "/indexes('shows')/docs/search?api-version=2015-02-28" json
|> JsonConvert.DeserializeObject<SearchResponse>
|> fun response -> response.value
Now that we can search the index, we'll use that in a recursive function to clear the index:
let rec clearIndex() =
let results = search "" "" 1000
if not <| Seq.isEmpty results then
results
|> Array.map (fun result -> { Action = "delete"; ShowId = result.ShowId })
|> fun ops ->
let json = JsonConvert.SerializeObject({ value = ops })
postJson "/indexes('shows')/docs/index?api-version=2015-02-28" json
|> ignore
clearIndex()
This will pull 1000 documents at a time, issuing delete operations for them until the index has been completely purged. With the current index size this only ends up being 6 or 7 requests so it's quite quick to process.
The API also exposes an endpoint to trigger an indexer run:
let rebuildIndex() =
postJson "/indexers/shows-indexer/run?api-version=2015-02-28" ""
|> ignore
Finally we just need the function definition itself:
let Run(inputMessage: string, log: TraceWriter) =
sprintf "Starting rebuild request for: %s" inputMessage |> log.Info
clearIndex()
rebuildIndex()
sprintf "Finished rebuild request for: %s" inputMessage |> log.Info
That may look like a lot, but all told, including logging, namespaces, and model definitions, it's only about 50 lines of code. That search function will also come in handy in future posts when we want to start doing some real searches against the indexes.
Now that this is wired up, I've got a complete data flow being triggered every day. Each morning the DownloadLineup function fires, which adds a new file to blob storage. That file triggers the ImportLineup function that updates the data in SQL Server and then places an item in the rebuild-requests queue. That queue triggers the final RebuildSearchIndex function to complete the flow. All told this only takes a couple minutes overall, but it's nicely split across discrete functions to keep things organized and also can be invoked on their own.
Summary
By adding in an Azure Search layer over my SQL Database I was easily able to add full text search functionality over the same data:
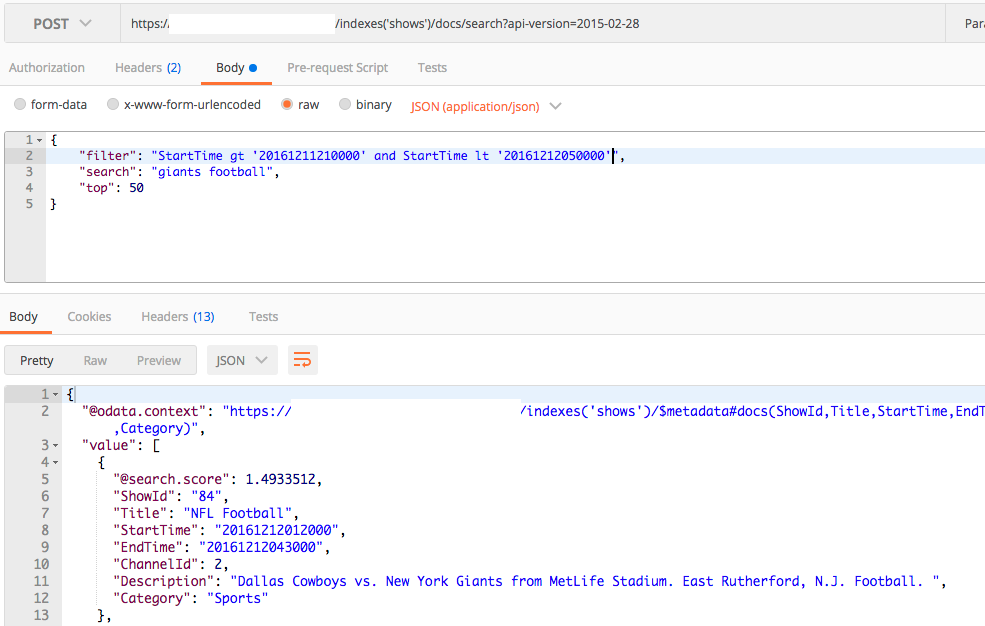
Now we're getting somewhere!
Next post in series: Part 3: The Device API