Akka.NET is a great toolkit for building concurrent and fault-tolerant systems by way of the actor model. Most think of actor systems as something you would just do on the server side of things, as part of building large distributed systems, but the approach works great for all sorts of applications. The recent release of Akka.NET 1.3 brought with it support for .NET Standard 1.6, so naturally I needed to try using it from a Xamarin app.
To give it a spin, I'll build a simple Xamarin.Forms app that takes a URL and begins crawling it for links, reports back what it finds, crawls those new links, and so on. Something like this wouldn't be too difficult to model without the actor model, but actors work really well for this type of scenario.
Message Types
Let's define some message types for communicating progress during the crawl. First, a command to initiate scraping a given URL:
public class Scrape
{
public string Url { get; }
public Scrape(string url) => Url = url;
}
Then we'll need a message to communicate the contents of a URL after it's downloaded:
public class DownloadUrlResult
{
public string Html { get; }
public DownloadUrlResult(string html) => Html = html;
}
Finally we need a message to communicate the final results of scraping a URL:
public class ScrapeResult
{
public string Url { get; }
public string Title { get; }
public IList<string> LinkedUrls { get; }
public ScrapeResult(string url, string title, IList<string> linkedUrls)
{
Url = url;
Title = title;
LinkedUrls = linkedUrls;
}
}
The Actor System
Now we can define some actors to do the work.
ScrapeActor
First we'll create an actor that is responsible for downloading and parsing a URL, and then messaging the results back to its parent:
public class ScrapeActor : ReceiveActor
{
public ScrapeActor(IActorRef parent)
{
Receive<Scrape>(msg => OnReceiveScrape(msg));
Receive<ScrapeResult>(msg => parent.Forward(msg));
}
private void OnReceiveScrape(Scrape msg)
{
var config = Configuration.Default.WithDefaultLoader();
BrowsingContext.New(config).OpenAsync(msg.Url).ContinueWith(request =>
{
var document = request.Result;
var links = document.Links
.Select(link => link.GetAttribute("href"))
.ToList();
return new ScrapeResult(document.Url, document.Title, links);
}, TaskContinuationOptions.ExecuteSynchronously).PipeTo(Self);
}
}
The downloading and parsing here is being done by the AngleSharp library which makes it really easy. When a message comes in saying to scrape a URL it downloads and parses that URL, and then when the result finishes it forwards that up the chain. Because this actor is focused on just doing one task at a time, we can potentially spin up as many of this concurrently as we need to speed up processing.
CoordinatorActor
With that actor ready to go, next we'll set up a coordinator actor that manages a pool of ScrapeActors:
public class CoordinatorActor : ReceiveActor
{
private readonly IActorRef _crawlers;
public CoordinatorActor()
{
_crawlers = Context.ActorOf(
Props.Create(() => new ScrapeActor(Self)).WithRouter(new SmallestMailboxPool(10)));
Receive<Scrape>(msg => _crawlers.Tell(msg));
Receive<ScrapeResult>(msg => OnReceiveScrapeResult(msg));
}
private void OnReceiveScrapeResult(ScrapeResult result)
{
foreach (var url in result.LinkedUrls)
_crawlers.Tell(new Scrape(url));
if (!string.IsNullOrWhiteSpace(result.Title))
Context.System.EventStream.Publish(result);
}
}
As scrape requests come in it sends those down to the worker in its pool with the smallest mailbox. This is where the actor model really shines, since you can easily adjust the size of the pool or the routing algorithm without actually making any real code changes. You could also load this entirely from configuration files to avoid code changes at all.
As results come in it sends new scrape requests back to the pool of workers in order to keep the crawling going, and then publishes the results to the event stream, which is a built-in publish/subscribe channel in Akka.NET.
ResultDispatchActor
Finally we'll create a small actor that will act as a bridge between the actor system and a view model driving the app's behavior (this will be defined shortly):
public class ResultDispatchActor : ReceiveActor
{
public ResultDispatchActor(MainViewModel viewModel) =>
Receive<ScrapeResult>(result => viewModel.Results.Add(result));
}
As results are received they are appended to the view model's list of results. One interesting thing to note here is that since an actor only processes one message at a time, you eliminate a lot of collection concurrency issues you might have to worry about otherwise.
Starting The System
Now that our actors are defined we just need to compose them into an actual actor system. For this all we'll just do that statically when the app starts:
public static class CrawlingSystem
{
private static readonly ActorSystem _system;
private static readonly IActorRef _coordinator;
static CrawlingSystem()
{
_system = ActorSystem.Create("crawling-system");
_coordinator = _system.ActorOf(Props.Create<CoordinatorActor>(), "coordinator");
}
public static void StartCrawling(string url, MainViewModel viewModel)
{
var props = Props.Create(() => new ResultDispatchActor(viewModel));
var dispatcher = _system.ActorOf(props);
_system.EventStream.Subscribe(dispatcher, typeof(ScrapeResult));
_coordinator.Tell(new Scrape(url));
}
}
Here we expose a StartCrawling method that takes in a URL and a view model, creates a bridge actor for that view model, and subscribes it to the stream of results.
The App
Now let's actually plug this into an app. First, let's define that MainViewModel class:
public class MainViewModel : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
public ObservableCollection<ScrapeResult> Results { get; } = new ObservableCollection<ScrapeResult>();
public ICommand StartCrawlingCommand { get; }
private string _url;
public string Url
{
get { return _url; }
set
{
_url = value;
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(nameof(Url)));
}
}
public MainViewModel() =>
StartCrawlingCommand = new Command(() => CrawlingSystem.StartCrawling(_url, this));
}
The view model exposes a URL property that can be bound to an entry field, a collection of results, and a command that initiates crawling for the given URL.
Now we can define the UI in XAML:
<?xml version="1.0" encoding="UTF-8"?>
<ContentPage xmlns="http://xamarin.com/schemas/2014/forms"
xmlns:x="http://schemas.microsoft.com/winfx/2009/xaml"
xmlns:akka="clr-namespace:MobileCrawler.CSharp;assembly=MobileCrawler.CSharp"
x:Class="MobileCrawler.CSharp.MainPage">
<ContentPage.Content>
<StackLayout Padding="15, 30, 15, 15" Spacing="10">
<StackLayout>
<Entry x:Name="Query" Text="{Binding Url}"
HorizontalOptions="FillAndExpand" Keyboard="Url"
Placeholder="Enter a URL" HeightRequest="40" FontSize="20">
<Entry.Behaviors>
<akka:EntryCompletedBehavior Command="{Binding StartCrawlingCommand}" />
</Entry.Behaviors>
</Entry>
</StackLayout>
<ListView ItemsSource="{Binding Results}">
<ListView.ItemTemplate>
<DataTemplate>
<TextCell Text="{Binding Title}" Detail="{Binding Url}" />
</DataTemplate>
</ListView.ItemTemplate>
<ListView.Header>
<StackLayout Orientation="Horizontal" Padding="10" Spacing="10">
<Label Text="{Binding Results.Count}" />
<Label Text="links crawled" />
</StackLayout>
</ListView.Header>
</ListView>
</StackLayout>
</ContentPage.Content>
</ContentPage>
In the code-behind all we need to do is set up the view model:
public partial class MainPage : ContentPage
{
public MainPage()
{
InitializeComponent();
BindingContext = new MainViewModel();
}
}
That's all we need - the view model and binding take care of the rest. Let's give it a shot:
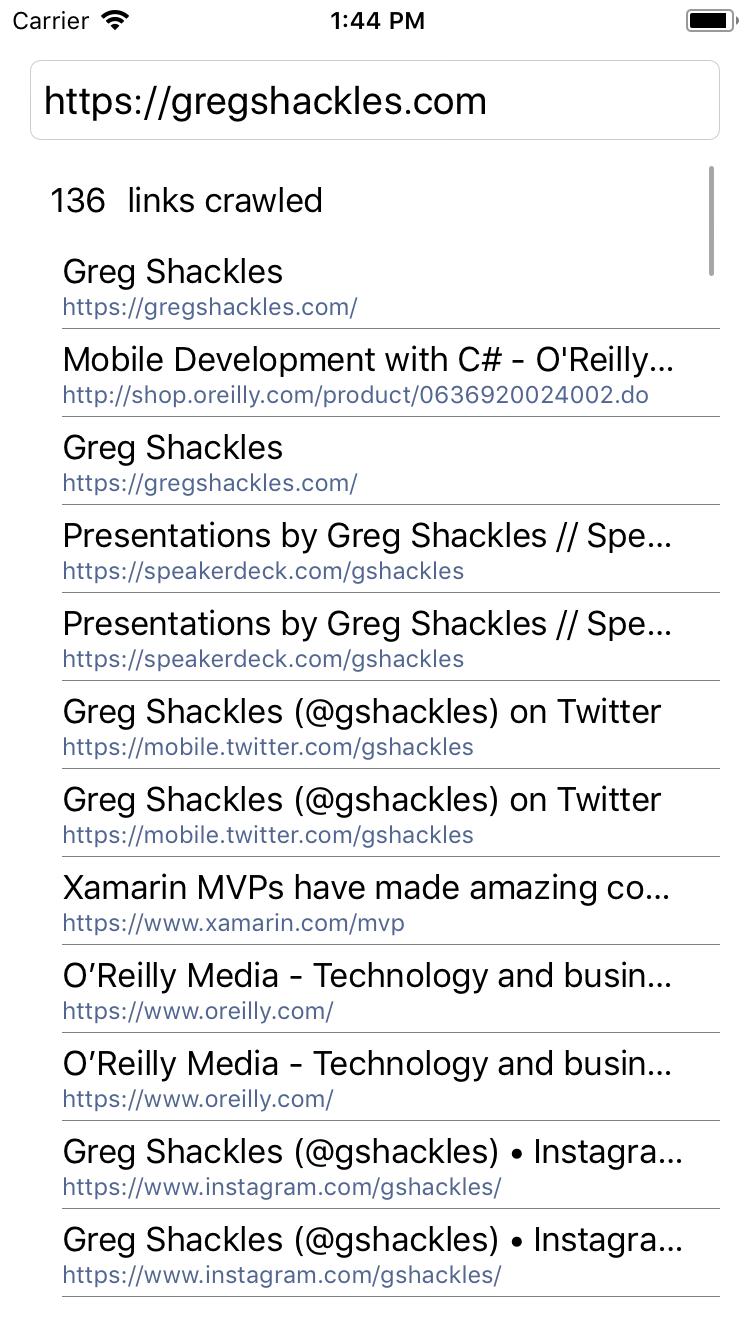
Not bad! This obviously only scratches the surface of what Akka can do, but I'm pretty excited to be able to start leveraging in Xamarin applications going forward. The full app can be found in my akka-samples repository on GitHub.